The Eye Beguiled
2. Vision as data-processing
Impossible objects and ambiguous figures are not things that can be handled in the literal sense: they arise in our brain. Since the perception process in the case of these figures follows a strange, non-routine pattern, the Viewer becomes aware that something is happening inside his head. For a better understanding of the process that we call "Vision", it is useful to have an idea of the manner in which our sense of sight (our eyes and our brain) processes light stimuli into meaningful information.
The eye as optical instrument

Figure 1. Anatomy of the eyeball.
The eye (fig. 1) works like a camera. The lens projects a reversed, reduced image of the outside world onto the retina - a network of photosensitive cells, lying opposite the pupil, which occupies more than half the interior of the eyeball. As an optical instrument, it has long been recognized as a small miracle. Whereas a camera is focused by moving the lens either closer to or away from the photosensitive layer, in the eye it is the refractive power of the lens itself which is adjusted during accommodation (adaptation to a specific distance). The shape of the eye lens is modified by means of the ciliary muscle: when the muscle contracts, the lens becomes rounder, whereby a focused image of nearby objects is cast onto the retina. The aperture of the human eye, too, can be adjusted just as in a camera. The pupil serves as the lens opening, which is widened or narrowed by the radial muscles which give the iris encircling the pupil its characteristic colour. As our eyes shift to the field we wish to focus upon, focal distance and pupil size are adjusted instantaneously and "fully automatically".

Figure 2. Cross-section of the retina

Figure 3. Eye with yellow spot
The structure of the retina (fig. 2), the photosensitive layer inside the eye, is complex. The optic nerve (together with the blood vessels) leads off from the back wall of the eye; there are no photosensitive cells at this point, which is known as the blind spot. The nerve fibres ramify and end in a succession of three different types of cell, which face away from the incoming light. Extensions leading from the third and innermost cell layer contain molecules which temporarily alter their structure as the light received is being processed, and which thereby emit an electrical impulse. The cells are called rods and cones after the shape of their extensions. The cones are colour-sensitive, whereas the rods are not; their photosensitivity, on the other hand, is far greater than that of the cones. One eye contains approximately one hundred million rods and six million cones, distributed unevenly across the retina. Exactly opposite the pupil lies the so-called yellow spot (fig. 3), which contains only cones in a particularly dense concentration. When we wish to see something in focus, we arrange for the image to fall on this yellow spot. There are many interconnections between the cells of the retina, and the electrical impulses from the one hundred million or so photosensitive cells are sent to the brain by just a million separate nerve fibres. The eye can thus be somewhat superficially described as a camera or television camera loaded with photosensitive film.

Figure 4. Kanizsa figure
From impulse to information

Figure 5. Illustration from Descartes' "Le traité de l'homme", 1664
But how do we actually see? Until recently, the question was barely addressed. The best anyone could do for an answer was merely the following: within the brain there is an area which specializes in vision; it is here that the retinal image is composed, albeit in brain cells. The more light that falls on a retinal cell, the more intense is the activity of its corresponding brain cell, so that the activity of the brain cells in our visual centre corresponds to the distribution of light upon the retina. In short, the process starts with an image on our retina and ends up with a matching picture on a small "screen" made up of brain cells. But this naturally still does not explain vision; it simply shifts the problem to a deeper level. For who is supposed to view this inner image? The situation is aptly illustrated in Figure 5, taken from Descartes' Le traité de l'homme. Here, all the nerve fibres end in the pituitary gland, which Descartes saw as the seat of the soul, and it is this which views the inner image. But the question still remains: how does this "viewing" actually proceed?

Figure 6.
The notion of a mini-viewer inside the brain is not merely insufficient to explain vision, but ignores three activities which are manifestly performed by the visual system itself. Looking at a figure by Kanizsa (fig. 4), for example, we see a triangle with three circle segments at its corners. This triangle is not present on the retina, however; it is an invention of the visual system! It is almost impossible to look at Figure 6 without seeing a continuous succession of different circular patterns, all jostling for dominance; it is as if we were directly experiencing inner visual activity. Many people find their visual system thrown into utter confusion by the Dallenbach figure (fig. 8), as they seek to interpret its black and white patches in a meaningful way. (To spare you this torment, Figure 10 offers an interpretation which your visual system will accept once and for all.) By contrast, you will have no trouble in reconstructing the few strokes of ink of Figure 7 into two people in conversation.

Figure 7. Brush drawing from the "Mustard Seed Garden Manual of Painting", 1679-1701
An entirely different method of seeing is illustrated by the investigations carried out by Werner Reichardt from Tubingen, for example, who spent fourteen years studying the visual flight-control system of the housefly, for which he was awarded the Heineken Prize in 1985. Like many other insects, the fly has compound eyes composed of many hundreds of individual rodlets and each forming its own photosensitive element. The flight-control system of the fly appears to be based on five independent sub-systems, or subroutines, which work rapidly (reacting approximately ten times faster than in humans) and efficiently. Its landing system, for example, operates as follows. When the fly's field of vision "explodes" (because a surface looms nearby), the fly banks towards its centre with a view to landing. If this centre lies above it, the fly automatically inverts to land upside down. As soon as its legs touch the surface, its "engine" is cut off. Once flying in a given direction, the fly extracts only two items of information from its field of vision: the point at which a moving patch of a specific size (which must match the size of a fly at a distance of 10 centimetres) is located within the visual field, and the direction and speed of this patch as it travels across the visual field. Processing of this data prompts automatic corrections to the flight path. It is extremely unlikely that the fly has a clear picture of the world around it. It sees neither surfaces nor objects; visual input is processed in such a way that the appropriate signals are transmitted directly to its motor system. Thus visual input is translated not into an image of an image, but into a form which allows the fly to react to its environment in an adequate manner. The same can also be said of an infinitely more complex system, such as the human being.

Figure 8. Dallenbach fugure
There are a number of reasons why scientists have long been kept from addressing the fundamental question of how man sees. There seemed to be so many other visual phenomena to explain first: the complex structure of the retina, colour vision, contrast phenomena, afterimages, etc. Contrary to expectations, however, findings in these areas still failed to shed light on the primary problem. Even more significant was the lack of any new overall concept or framework within which visual phenomena could be ordered. The relative narrowness of the conventional field of enquiry can be deduced from an excellent manual on visual perception compiled by T.N. Comsweet, based on his lectures for first- and second-term students. The author notes in his preface: "I seek to champion (in this book) what I hold to be the fundamental themes underlying the vast field which we loosely describe as visual perception." Examining the contents of his book, however, these "fundamental themes" turn out to be the effect of light on the cones and rods of the retina, colour vision, the way in which sensory cells can increase or reduce the extent of their mutual influence, the frequency of the electrical signals transmitted via the sensory cells and facial nerves, and so on. Research in this field is today following entirely new paths, as evidenced by the confusing diversity in the specialist press. Only the expert can form a picture of the "new science of Vision" currently emerging. There has been just one attempt to integrate some of its new ideas and findings into traditional thinking on visual perception in a manner accessible to the layman. Yet even here the questions "What is Vision?" and "How do we see?" are not made the central focus of discussion.
From image to data-processing
It was David Marr, from the Artificial Intelligence Laboratory at the
Massachusetts Institute of Technology, who made the first, admirable attempt to
approach the subject from an entirely new angle in his book Vision, published
posthumously. At a time which barely seemed ripe for such a discussion, he
sought to address the core problem and propose possible solutions. Marr's
findings are certainly not definitive and are today open to challenge on many
points, but his book nevertheless has the advantages of logic and consistency.
At all events, Marr's approach offers us a very useful background against which
to plot the positions of impossible objects and ambiguous figures. We shall
therefore attempt, in the following pages, to trace a broad outline of Marr's thought.
Marr described the shortcomings of conventional perception theory as follows:
"Trying to understand perception by studying only neurons is like trying to understand bird flight by studying only feathers: It just cannot be done. In order to understand bird flight, we have to understand aerodynamics; only then do the structure of feathers and the different shapes of birds’ wings make sense." In this context, Marr names J.J. Gibson as one of the first to concern himself with meaningful questions of this kind in the field of vision. Gibson's important contribution, according to Marr, was to note "that the important thing about the senses is that they are channels for perception of the real world outside (...) He therefore asked the critically important question, How does one obtain constant perceptions in everyday life on the basis of continually changing sensations? This is exactly the right question, showing that Gibson correctly regarded the problem of perception as that of recovering from sensory information 'valid' properties of the external world." And thus we reach the field of information processing.
It is not a question of Marr wishing to ignore other possible explanations of the phenomenon of vision. On the contrary, he expressly emphasizes that vision cannot be explained satisfactorily from one angle alone. Explanations have to be found for everyday experiences which agree with the findings of experimental psychology and the totality of the discoveries made by physiologists and neurologists concerning the anatomy of the nervous system. As regards information processing, the computer scientist would like to know just how such a visual system can be programmed and what the best algorithms are for the job. In short, he asks how vision can be programmed. Only a comprehensive theory can be accepted as a satisfactory explanation of the vision process.
Marr worked on the problem from 1973 to 1980. Unfortunately, he was unable to finish his work, but he laid the foundation stone for further research into those areas which he was no longer in a position to explore for himself.
From neurology to the vision machine
The conviction that many human functions were controlled by the cerebral cortex was shared by neurologists from the early nineteenth century onwards. Opinions differed as to whether the individual functions were governed by a clearly-defined part of the cerebral cortex, or whether the brain in its entirety was involved in every function. A now famous experiment by the French neurologist Pierre Paul Broca led to the general recognition of the specific-location theory. Broca was treating a patient who had been unable to speak for ten years, despite lacking none of his vocal chords. When the man died in 1861, an autopsy revealed that a part of the left side of his brain was deformed. For Broca, it was thus clear that speech was governed by this particular section of the cerebral cortex. His theory was confirmed by subsequent examinations of people suffering brain lesions, and it was eventually possible to map out the centres of the various vital functions on the human brain.
Figure 9. The response of two different brain cells to optical stimuli with different directions on retina
A century later, in the 1950s, D.H. Hubel and T.N. Wiesel began experimenting with the brains of living apes and cats. In the visual centre in the cerebral cortex they discovered nerve cells which are particularly sensitive to horizontal, vertical and diagonal lines in the visual field (p. 15, fig. 9). Their sophisticated microsurgical techniques were subsequently adopted by other scientists.
The cerebral cortex thus houses not only the centres of various functions, but within such a centre, e.g. the visual centre, certain nerve cells which are only activated by the arrival of very specific signals. These are signals issuing from the retina which correlate to well-defined situations in the outside world. It was now assumed that information about various shapes and spatial arrangements lay openly accessible within the visual memory and that the information from the activated nerve cells was compared to this stored information.
This detector theory influenced the direction of research into visual perception in around 1960 - the same direction as that being pursued by scientists concerned with "artificial intelligence". The computerized simulation of the processes of human sight by a so-called "vision machine" was considered one easily attainable goal of such research. But things proved otherwise: it soon became clear that it was virtually impossible to write programmes which were capable of recognizing changing light intensities, shadow effects and surface structure, and of sorting the confusion of complex objects into meaningful patterns. Furthermore, such object recognition processes demanded an unlimited memory capacity, since images of infinite numbers of objects needed to be stored in countless different variations and lighting situations.
No further advances in the field of the visual recognition of a real environment appeared possible. Doubt began to arise whether computer hardware could ever hope to simulate the brain: when compared to the human cerebral cortex, in which each nerve cell has an average of 10,000 connections linking it to other nerve cells, the equivalent computer ratio of just 1:1 seems barely adequate!

Figure 10. Solution of the Dallenbach fugure
Elizabeth Warrington's lecture
In 1973 Marr attended a lecture given by the British neurologist Elizabeth Warrington. She discussed how a large number of the patients she had examined with parietal lesions on the right side of their brain were perfectly able to recognize and describe a variety of objects, on condition that the objects were seen in their conventional form. Such patients could identify without difficulty a bucket seen side-on, for example, but were unable to recognize the same bucket seen end-on. Indeed, even when told they were looking down at a bucket from above, they vehemently refused to believe it! Even more surprising was the behaviour of those patients suffering lesions on the left side of the brain. Such patients often had no language and were therefore unable to name the object they saw or state its purpose. They were nevertheless able to convey that they correctly perceived its geometry, irrespective of the angle from which they were seeing it. This prompted Marr to observe: "Warrington’s talk suggested two things. First, the representation of the shape of an object is stored in a different place and is therefore a quite different kind of thing from the representation of its use and purpose. And second, vision alone can deliver an internal description of the shape of a viewed object, even when the object was not recognized in the conventional sense of understanding its use and purpose... Elizabeth Warrington had put her finger on what was somehow the quintessential fact of human vision - that it tells about shape and space and spatial arrangement." If this is indeed so, those scientists active in the field of visual perception and artificial intelligence (in as far as they are working on vision machines) will have to exchange the detector theory of Hubel's experiments for an entirely new set of tactics.
The module theory

Figure 11. Random-dot stereogram by Bela Julesz, and the floating square
A second of Marr's starting-points (and here, too, he looks back in part to Warrington's work) is his conviction that our sense of sight has a modular structure. In computer language, this means that our master programme "Vision" embraces a range of subroutines each of which is entirely independent of the rest and can also operate entirely independently of the rest. A clear example of one such subroutine or module is stereopsis, whereby depth is perceived as a result of each eye being offered a slightly different image. It was formerly generally held that, in order to be able to see in three dimensions, we first recognize viewed images as such and only subsequently decide whether the objects are near or far away. In 1960 Bela Julesz, who was also awarded the Heineken Prize in 1985, was able to demonstrate that spatial perception with two eyes derives solely from the processing of small differences between the two retinal images. It is thus possible to perceive depth even where absolutely no objects are present or even suggested. For his experiments, Julesz devised stereograms made up of randomly-distributed dots (fig. 11). The image seen by the right eye is identical to that seen by the left in all but a central square region, which has been cut out, shifted a little to one side and stuck down again onto the background. The white gap left behind was then filled with a random pattern of dots. If the two images (in which no "representation" can be recognized) are viewed through a stereoscope, the square that was cut out appears to float in front of the background. Such stereograms contain spatial data which are processed automatically by the Visual system. Stereopsis is thus an autonomous module contained within our Vision. This module theory proved highly fruitful.
From the two-dimensional retinal image to the three-dimensional model

Figure 12. During the visual process, the retinal image (left) is translated into a primal sketch in which intensity changes become apparent (right)
Vision is a multi-stage process which transforms two-dimensional representations of the outside world (retinal images) into useful information for the Viewer. It starts from a two-dimensional retinal image, which - ignoring colour Vision for the time being - records only degrees of light intensity. As the first stage, involving just one module, these degrees of intensity are translated into intensity changes - in other words, into contours, which indicate sudden alterations in light intensity. Marr states precisely which algorithm is thereby involved (expressed mathematically, incidentally, the transformation is a fairly complex one), and how the perception and nerve cells are able to perform this algorithm. The result of this first stage is what Marr calls a "primal sketch", which offers a summary of intensity changes, their mutual relationship, and their distribution across the visual field (fig. 12). This is a significant step, since in the visible world intensity changes frequently correspond to the natural contours of objects. The second stage leads to what Marr calls a "2½-D sketch". The 2½-D sketch maps the orientation and depth of visible surfaces around the viewer, thereby drawing upon information from not one but several different modules. Marr coins the rather unwieldy notion of "2½-dimensional" in order to emphasize that we are dealing with spatial information from the angle of the Viewer: a 2½-D sketch is thus a representation which still suffers from perspective distortions and which cannot yet be directly compared to actual spatial arrangements. The drawing of a 2½-D sketch shown here (fig. 13) simply illustrates for our purposes some of the different pieces of information processed in such a sketch; no image of this kind is actually produced inside our brain, however.
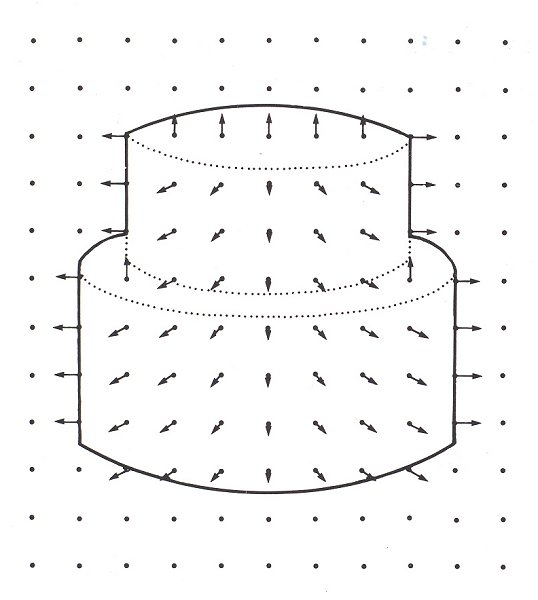
Figure 13. Drawing of a 2 1/2-D sketch - "a viewer-centred representation of the depth and orientation of Visible surfaces" (Marr)
So far the visual system has been operating, via a number of modules, autonomously, automatically and independently of data on the outside world stored in the brain. During the final stage of the process, however, it is possible that reference is made to existing information. This last stage delivers a 3-D model: a stable description independent of the angle of the viewer and directly suitable for comparison with the visual information stored in the brain.
According to Marr, the component axes of a shape play a major role in the constitution of the 3-D model. Those to whom this notion is unfamiliar may find it a little far-fetched, but there is indeed some evidence which seems to support it. First, many objects from our environment (in particular animals and plants) can be portrayed quite effectively in simple pipe-cleaner models. The fact that we are still able to recognize them lies in our identification of the reproduction of their natural axes (fig. 14).

Figure 14. Simple animal models can be identified from their component axes
Secondly, this theory offers a plausible explanation for the fact that we are able to visually dismantle an object into its various parts. This faculty is reflected in our language, which gives different names to each part. Thus, in describing the human body, designations such as "body", "arm"and "finger" indicate a differentiation according to component axes (fig. 15).
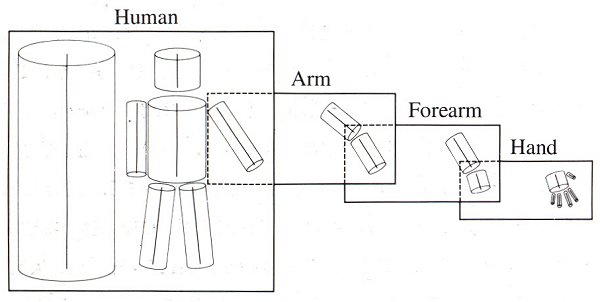
Figure 16. The model axis (left) breaks down into component axes (right)
The theory thirdly accords with our ability to generalize and at the same time differentiate between shapes. We generalize by grouping together objects with the same main axes, whereas we differentiate by analyzing their subsidiary axes, such as the boughs of a tree. Marr gives the algorithms with which the 3-D model is calculated from the 2½-D model; this, too, is a largely autonomous process. Marr himself notes that these algorithms only work where clear axes are present. In the case of a crumpled piece of paper, for example, possible axes may be hard to identify, and will offer an algorithm almost no point of application.
The link between the 3-D model and the visual images stored in the brain only becomes active in the process of the recognition of an object.
It is here that a large gap still yawns in our knowledge. How are these visual images stored? How does the recognition process unfold? How does the comparison between existing images and the 3-D image currently being composed actually proceed? This last point is touched upon by Marr (fig. 16), but a great deal of scientific ground will have to be covered before any more clarity or certainty is gained.
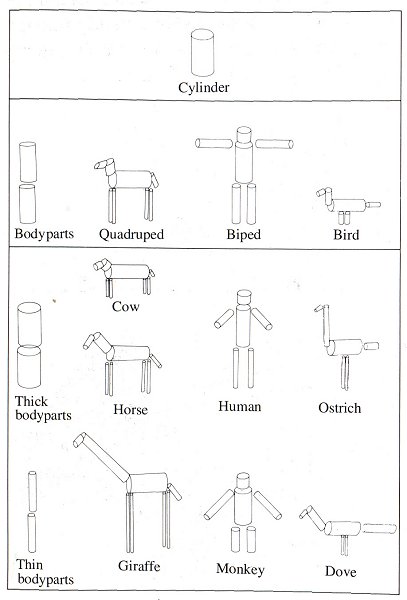
Figure 16. New shape descriptions are related to stored shapes in a comparison which moves from the general (above) to the particular (below)
Although we ourselves are unconscious of the Various phases in which Visual information is processed, a number of clearly-demonstrable parallels exist between these phases and the different ways in which, over the course of history, we have rendered our impressions of space on a two-dimensional surface.
Thus the Pointillists emphasize the contourless retinal image, while line drawings correspond to the stage of the primal sketch. A Cubist painting might be compared to the processing of Visual data in preparation for the final 3-D model, although this was undoubtedly not the intention of the original artist.
Man and computer
In his comprehensive approach to the subject, Marr sought to show how we can understand the process of Vision without having to call upon knowledge which is already available in the brain.
He thereby opened up a new avenue for researchers of Visual perception. His ideas can be used to steer a more efficient course towards the realization of a Vision machine. When Marr was writing his book, he must have been aware of the effort which his readers would be required to exert if they were to follow his new ideas and their implications. This can be sensed throughout the work and surfaces most forcibly in the last chapter, "In Defense of the Approach". It is a polemic "justification" lasting a good 25 pages in which he seizes one last opportunity to argue his cause. In this chapter he holds a conversation with an imaginary sceptic, who attacks Marr with arguments such as the following:
"I'm still unhappy about this tying-together process and the idea that from all that wealth of detail all you have left is a description. It sounds too cerebral somehow... As we move closer to saying the brain is a computer, I must say I do get more and more fearful about the meaning of human values."
Marr offers an intriguing reply: "Well, to say the brain is a computer is correct but misleading. It's really a highly specialized information-processing device - or rather, a whole lot of them. Viewing our brains as information-processing devices is not demeaning and does not negate human values. If anything, it tends to support them and may in the end help us to understand what from an information-processing view human values actually are, why they have selective value, and how they are knitted into the capacity for social mores and organization with which our genes have endowed us."